
studio1804 is an independent AI research lab.
Our work centers on systems that handle real-world complexity in language, archives, evidence, and the infrastructure that makes them trustworthy. Each project takes the institutional shape its mission requires.
Project — Rasin
Explore Haiti's history through the sources themselves.
Rasin helps researchers, students, journalists, and Haitian diaspora communities explore Haiti and its diaspora through original documents. Ask questions in plain language, move across French, Kreyòl, English, and Spanish records, and trace every answer back to the page it came from.
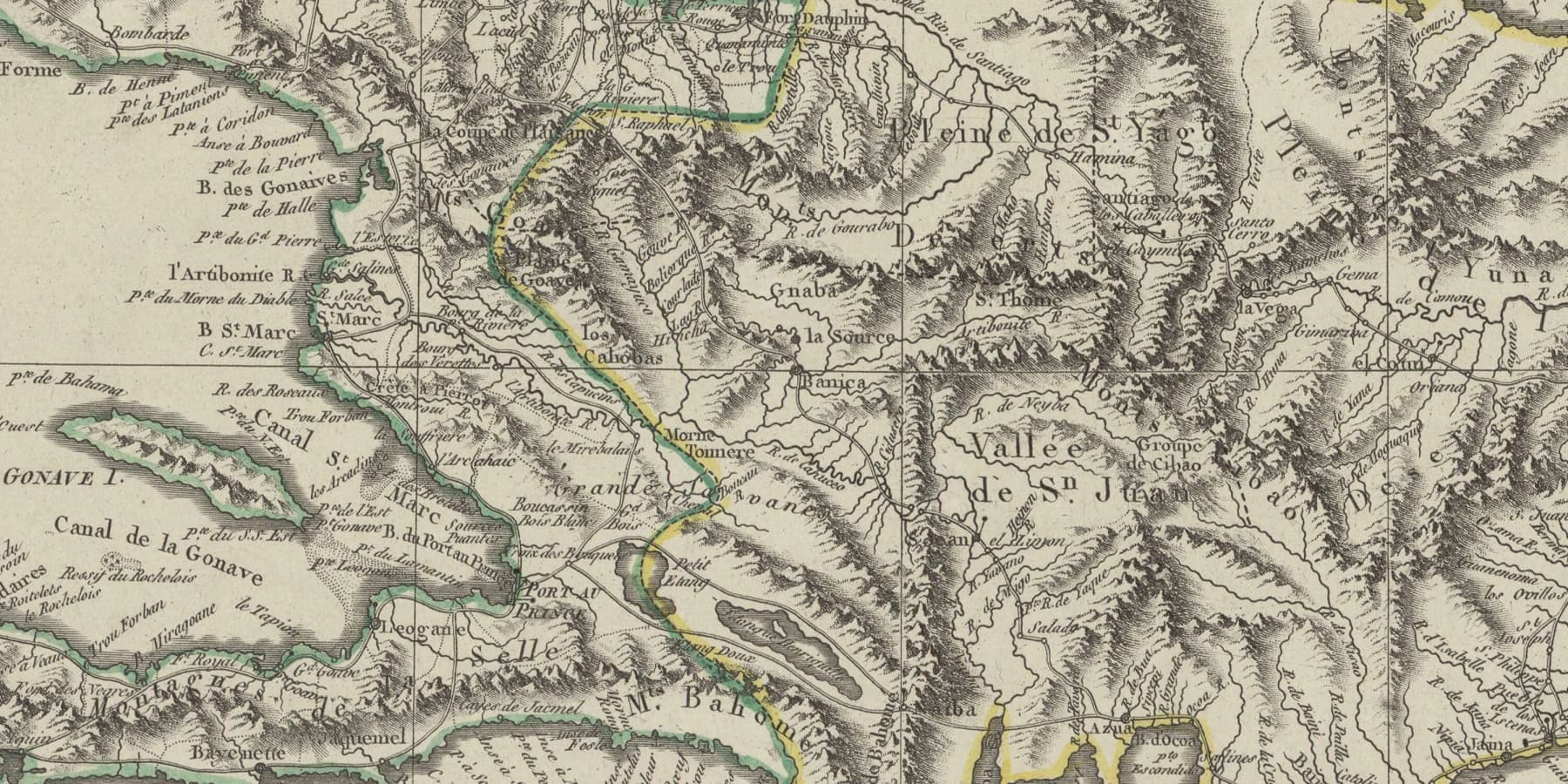
Detail — archival source, Rasin corpus

Public-knowledge systems
Rasin is the current public implementation: a source-cited system for exploring Haiti and its diaspora through original records.

Multilingual retrieval
Active work on OCR, embeddings, search, and evaluation for records that move across languages, spellings, and archival silos.
Evidence and provenance
Citation verification, entity resolution, claim provenance, and correction workflows for systems that need to stay close to their sources.
Infrastructure in formation
Portable archive infrastructure and AI security work for systems that use external tools, services, and private data.
Public-knowledge systems
Rasin is the current public implementation: a source-cited system for exploring Haiti and its diaspora through original records.
Explore ›Multilingual retrieval
Active work on OCR, embeddings, search, and evaluation for records that move across languages, spellings, and archival silos.
Explore ›Evidence and provenance
Citation verification, entity resolution, claim provenance, and correction workflows for systems that need to stay close to their sources.
Explore ›Infrastructure in formation
Portable archive infrastructure and AI security work for systems that use external tools, services, and private data.
Explore ›Membership
studio1804 is a member of the NVIDIA Inception program.
NVIDIA Inception gives studio1804 access to GPU-accelerated compute for active work in OCR at scale, multilingual retrieval, and entity indexing across hundreds of thousands of historical documents.